

An increasing number of websites heavily use Javascript frameworks such as React, AngularJS, Vue.js, Polymer, and Ember. Crawling Javascript-heavy websites poses challenges as the content is dynamically generated, and crawlers can only collect content from static websites.
Websites that utilize data transfer from the server and render the content asynchronously with Javascript are referred to as AJAX websites, and the act of crawling these sites is referred to as dynamic or AJAX crawling.
AddSearch supports AJAX crawling, but if you’re looking for ways to make your Javascript-heavy website crawler-friendly for other search engines, head on over to the next sections of this article and find out more.
What is Crawling?

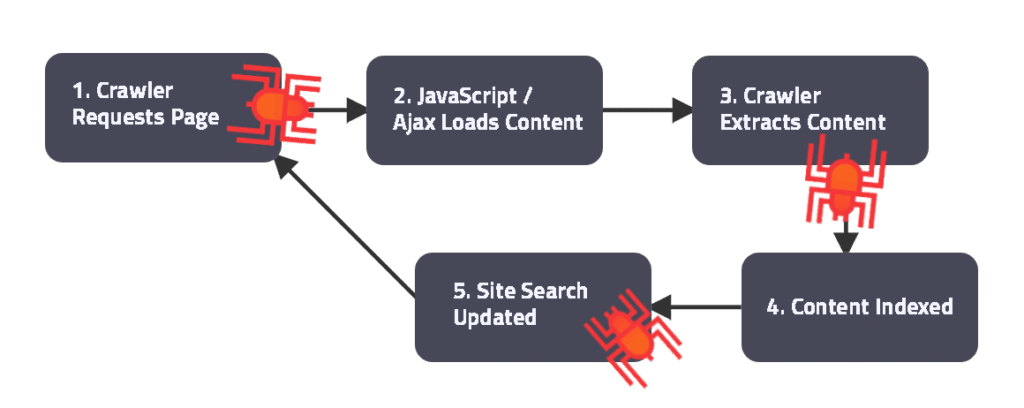
Crawling refers to the process of collecting content from a website and indexing it in an index that can be accessed by the search engine. Crawling is carried out by the crawler, which is an application that visits a website, searches for links to its web pages, and collects them.
Usually, the start- or homepage acts as what is called the seed page. This is where the crawler begins the process of searching for links to the pages of the website. When the crawler finds links from a page, it follows them to the other pages the links refer to. Then it follows the links found from the other pages and reiterates this procedure until there are no new links to follow. During this process, all of the links to the pages are collected. In addition to the seed page, the crawler can utilize the links found from a sitemap.
When the crawler has iterated through the links, the web pages or a set of selected content from the web pages is requested. Requesting selected content from web pages is referred to as scraping, which is a subset of crawling. In this article, we will refer to crawling in general instead of scraping in the context of requesting selected content from web pages.
The requested content is saved to a database that is structured as an index which is also referred to as indexing. What this means is that the selected content crawled from each web page has a reference document that holds the selected contents in the index.
So, when a visitor uses a search engine to find content, the search result includes the crawled content as well as a link to the web page where the content was crawled.
Ajax Crawling – Rendering Before Crawling
AJAX websites offer visitors a rich interactive user experience without having to load the whole web page each time they consume new content. While the user experience may be great, requesting content from AJAX web pages creates some challenges.
On static web pages, the content can be found from the page source. On AJAX web pages, however, most of the content is generated dynamically using AJAX technologies to transfer and render the content after the page is loaded and the scripts are executed.
Crawlers are able to crawl static web pages but crawling dynamically generated content is not possible. This is because crawlers are not able to execute the scripts that render the content visible to the visitor and into the memory of the web browser.
If crawlers can’t execute AJAX requests, how does AJAX crawling work?
In short, the web page needs to be loaded with a browser where the AJAX requests and the Javascript that renders the page elements visible are executed.
Only after this can the AJAX page be exported as a static HTML page, which can then be requested and indexed. This process is referred to as prerendering.
Two Ways of Prerendering AJAX Web Pages
The idea of prerendering is to make websites crawler-friendly to any search engine that crawls and indexes websites. This is made possible by making static HTML snapshots of the website’s web pages. Thus, prerendering an AJAX site is also a form of Search Engine Optimization (SEO).
Prerendering can be established with libraries and frameworks that can be used with various programming languages. Service providers also provide prerendering through middleware that gives separate responses to crawler and user requests.
Automation Frameworks And Headless Browsers
Some of the programming languages used for crawling web pages are Python and Javascript (with Node.js runtime.) When crawling AJAX web pages the programming languages are used in conjunction with automation frameworks, such as Selenium, and with so-called headless browsers.
Selenium is a browser automation framework with which automating interaction with the browser is fairly easy to set up. While Selenium is not mandatory for AJAX crawling, it is handy if the visitor’s interactions —for instance, iterating through paginated AJAX content that needs user interaction—are needed for crawling the content.
A headless browser is a web browser without a graphical interface. Thus, it can be used from a command line—for instance, from a web server. The most common headless browsers that can be used for prerendering are PhantomJS, Headless Chrome, and Firefox Headless Mode.
Headless browsers are the most important components of prerendering dynamically generated AJAX web pages into crawlable static HTML pages. As stated earlier in this article, browsers are used as tools to request AJAX content and run Javascript, which renders the content to the browser’s memory.
Prerendering As A Service
Prerendering can also be acquired as a service. The service includes prerendering which saves AJAX pages to static HTML pages. It also supports middleware which has separate responses to crawler and user requests.
The user request normally routes the visitor to the dynamically generated page, which the browser can render visible by making AJAX requests and executing Javascript. As crawlers can only crawl static HTML content, the middleware routes the crawler’s request to the static HTML page prerendered by the prerendering service provider. The middleware recognizes the crawler’s request by using the crawler’s user agent.
The idea behind the prerendering service is to make AJAX website crawler friendly, thus providing the possibility for SEO. One of the commercial services is the open-source-based Prerender.io, which can also be installed on a web server.
How to Crawl JavaScript Websites
JavaScript has become the language of the internet, powering many of the dynamic, interactive websites we use daily. Libraries and frameworks like React, Angular, and Vue have made it easier than ever to create rich, user-friendly web experiences. But as the web has evolved, so too have the challenges for search engines and site owners who need to ensure their content is discoverable. This is where Ajax crawling comes into play.
JavaScript and Ajax Crawling

AJAX (Asynchronous JavaScript and XML) is a technique that allows web pages to update and display new data without reloading the entire page. AJAX crawling is the process of indexing these dynamically generated web pages.
When a web crawler encounters a JavaScript website, it can’t see the dynamic content that’s generated by JavaScript code. It only sees the initial loaded HTML document, which often doesn’t include the meaningful content that users interact with.
We use AJAX crawling to make this dynamic content visible to web crawlers. This involves running the JavaScript code and generating a static HTML snapshot of the page, which the crawler can then index.
AddSearch and AJAX Crawling
AddSearch is a search solution that supports AJAX crawling, enabling indexing dynamic content from JavaScript websites. When AddSearch crawls your website, it can execute JavaScript code and render the dynamic content, ensuring that this content is included in the search index.
This means that if your website uses JavaScript to load important content, AddSearch can still make this content searchable. Whether your site uses React, Angular, Vue, or any other JavaScript framework, AddSearch can crawl and index your dynamic content.
Conclusion
Crawling is a process through which a website’s pages are indexed for use by a search engine. AJAX crawling, however, requires a few extra steps to convert the dynamic content into a static format that can be crawled.
You can do this by setting up an environment with programmable frameworks associated with headless browsers. Services also make it easier to serve static content to crawlers.
If you prefer a service that takes care of AJAX crawling and provides you with an internal search engine that is easy to set up on your page, contact our sales and order a demo.
FAQs about AJAX Crawling
What is AJAX best used for?
AJAX (Asynchronous JavaScript and XML) is best used for creating dynamic, fast-loading web pages that don’t require a full refresh. It lets you update parts of a webpage—like loading new content or submitting forms—without interrupting the user experience. Think of it like flipping through pages of a book without closing it each time; AJAX keeps things smooth, quick, and uninterrupted.
What is the full form of AJAX?
The full form of AJAX is Asynchronous JavaScript and XML. It’s a web development technique that lets you update parts of a webpage without reloading the entire page, making your site feel faster and more interactive. It’s like sending a text without needing to wait for a new conversation to start every time.
Does Google still use AJAX?
Yes, Google still uses AJAX! In fact, many of Google’s apps and services, like Gmail and Google Maps, rely on AJAX to deliver smooth, real-time updates without page reloads. It helps keep things fast and responsive, so users can interact with content without interruption—just one of the reasons Google’s experience feels so seamless and dynamic.
Is AJAX better than PHP?
AJAX and PHP aren’t exactly rivals—they’re more like teammates! AJAX is great for creating smooth, interactive user experiences by updating parts of a page without reloading, while PHP handles the server-side logic, like processing data or managing databases. Together, they can work wonders: AJAX keeps things fast and dynamic on the front end, and PHP takes care of the heavy lifting behind the scenes. So, it’s not about one being better than the other; it’s about using them together to create a powerful, seamless web experience!
